mannynajera.com
04/12/13: Lambdas within lambdas, and vectors of vectors of tuples
One of the things that I have wanted to experiment with for quite some time is forex. Specifically, I've always been intrugued by the sheer volume of data represented, and how one would go about processing and visualizing it all.
Another recent interest of mine has been the new C++11 standard. Lambdas in particular. I also wanted to try to write some code in a very "C++11" way, which for me means the following:
* Using STL containers for everything (everything appropriate, that is)
* Using std::for_each instead of for loops
* Using lambdas
* Using some of the newer features of C++11, such as std::tuple and std::regex
So, to combine these two things, I created a simple program, fxmapper, to read in a set of daily average price data for a number of currency pairs and organize them in a particular way.
Given a set of prices for a number of currency pairs:
a0, a1, a2, a3, a4, a5, a6, a7
b0, b1, b2, b3, b4, b5, b6, b7
c0, c1, c2, c3, c4, c5, c6, c7
d0, d1, d2, d3, d4, d5, d6, d7
e0, e1, e2, e3, e4, e5, e6, e7
The program reorganizes the data such that:
a0, b0, c0, d0, e0
a1, b1, c1, d1, e1
a2, b2, c2, d2, e2
a3, b3, c3, d3, e3
a4, b4, c4, d4, e4
a5, b5, c5, d5, e5
a6, b6, c6, d6, e6
a7, b7, c7, d7, e7
Sorting each row in the resulting table would therefore give some indication of the performance of a currency pair relative to the others. Ideally, processing the data at a high enough resolution (using all pairs, and doing a tick-by-tick comparison instead of daily) would produce some meaningful information as to how different currency pairs correlate (or do not correlate) over time.
The fxmapper program performs a very basic implementation of this. The output can be seen here:
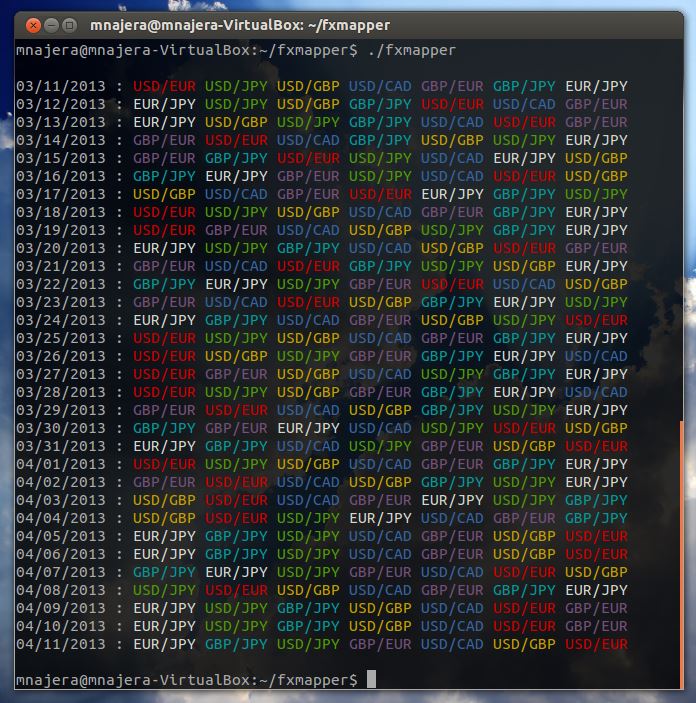
The data file used for input is here. The price information came from OANDA's fxHistory Classic tool. I grabbed the daily average price output in CSV format. The label of the currency pair was added before each run of CSV data.
The first big suprise for me was how easy it is to use std::regex for parsing input. I've never been a Perl person (and while I do use sed, I admit to being scared every time I'm called upon to do so), so regexes have always made me uneasy. It didn't take me very long to figure out how to do basic regex matching here, and it's something that I'm going to be using a lot more of in the future.
Lambdas seem to have come fairly natural for me, too. I tend to use a lot of anonymous inner classes in Java, so I think that experience helped. The error messages were helpful in cases where a variable wasn't being captured (contrast that with the barfing you get for a template error).
This code came together in a few hours, and isn't meant to be production quality, but it does work, and hopefuly it will inspire me to tackle larger forex/C++11 projects.
The code listing is below, but you can download it here.
// *******************************************************************
// fxmapper.cpp
// Manny Najera (manny.najera@gmail.com)
//
// This program reads FX data from an input file matching the
// following format:
//
// AAA/BBB
// mm/dd/yyyy,###.##
//
// Where "AAA/BBB" is a currency pair, and "mm/dd/yyyy,###.##" is
// price information for a specific date.
//
// The rate of change between each subsequent entry for each currency
// pair is calculated, and the rate of change among all the currency
// pairs are sorted among themselves for each date. The output of
// the program is a table that displays each currency pair in
// ascending order of the change rate for the given day.
//
// The general idea is that the correlations between different
// currency pairs (two pairs moving together, or not moving
// together) might yield useful information.
//
// The real value of this demo program is to demonstrate the use
// of the following C++11 concepts:
//
// * use of the STL (especially std::for_each)
// * std::regex
// * std::tuple
// * lambdas (and nested lambdas)
#include <fstream>
#include <iostream>
#include <iomanip>
#include <string>
#include <regex>
#include <vector>
class ParsedInput {
private:
std::vector<std::string> _vecLabels;
std::vector<std::string> _vecDates;
std::vector<std::vector<double>> _vecValues;
std::vector<std::vector<double>> _vecChangeRates;
bool _hasError = false;
public:
ParsedInput(const char *filename);
std::vector<std::string> const &getVecLabels() { return _vecLabels; };
std::vector<std::string> const &getVecDates() { return _vecDates; };
std::vector<std::vector<double>> const &getVecValues() { return _vecValues; };
std::vector<std::vector<double>> const &getChangeRates() { return _vecChangeRates; };
const bool &getHasError() { return _hasError; };
};
int main() {
ParsedInput pi("data.txt");
if (pi.getHasError()) {
std::cout << "Error parsing input." << std::endl;
return -1;
}
auto labels = pi.getVecLabels();
auto dates = pi.getVecDates();
auto changeRates = pi.getChangeRates();
int numElements = changeRates.size();
int numPointsPerElement = changeRates[0].size();
// create a vector of tuples that corresponds to each
// "column" of our table
std::vector<std::vector<std::tuple<std::string, double>>> column(numPointsPerElement);
std::for_each(begin(column), end(column), [&](std::vector<std::tuple<std::string, double>> &c) {
c.resize(numElements);
});
// fill each tuple with data from the value vectors
int column_index = 0;
std::for_each(begin(column), end(column), [&](std::vector<std::tuple<std::string, double>> &c) {
int row_index = 0;
std::for_each(begin(c), end(c), [&](std::tuple<std::string, double> &t) {
std::get<0>(t) = labels[row_index];
std::get<1>(t) = changeRates[row_index][column_index];
row_index++;
});
column_index++;
});
// sort each column of tuples according to their value (which is the second element)
// in descending order
std::for_each(begin(column), end(column), [](std::vector<std::tuple<std::string, double>> &c) {
std::sort(begin(c), end(c), [](std::tuple<std::string, double> a, std::tuple<std::string, double> b) {
return std::get<1>(a) > std::get<1>(b);
});
});
// display the resulting ordering for each time slice
std::cout << std::endl;
int dateIndex = 0;
std::for_each(begin(column), end(column), [&](std::vector<std::tuple<std::string, double>> &c) {
// the date is displayed in white
std::cout << "\x1b[0m";
std::cout << dates[dateIndex++] << " : ";
std::for_each(begin(c), end(c), [&](std::tuple<std::string, double> &t) {
// a bit silly: choose a color based on where in the
// label vector the current tuple value appears
// (the ANSI color prefix could instead be added to the
// label string itself...)
int selectedColorIndex = 0;
int colorIndex = 0;
std::for_each(begin(labels), end(labels), [&](std::string &label) {
if (label == std::get<0>(t)) {
selectedColorIndex = colorIndex;
}
colorIndex++;
});
std::cout << "\x1b[" << (31 + selectedColorIndex) << "m";
std::cout << std::get<0>(t) << " ";
});
std::cout << std::endl;
});
// revert back to plain white for console output
std::cout << "\x1b[0m" << std::endl;
return 0;
}
ParsedInput::ParsedInput(const char *filename) {
std::fstream fs;
bool doAddDates = true;
fs.open(filename, std::fstream::in);
if (fs.fail()) {
_hasError = true;
return;
}
while(!fs.eof()) {
std::string s;
getline(fs, s);
// match strings in the format "USD/JPY"
if (std::regex_match(s, std::regex(".../..."))) {
// if we are not adding the first label, we aren't
// going to store any more date fields
if (_vecLabels.size() >= 1) {
doAddDates = false;
}
_vecLabels.push_back(s);
std::vector<double> v;
_vecValues.push_back(v);
}
// match strings in for format "mm/dd/yyyy,123.45"
if (std::regex_match(s, std::regex("../../....,.+"))) {
double value = 0.0;
value = atof(s.substr(s.find_first_of(",") + 1).c_str());
_vecValues[_vecValues.size() - 1].push_back(value);
if (doAddDates) {
_vecDates.push_back(s.substr(0, s.find_first_of(",")));
}
}
}
// calculate the rate of change between subsequent values
std::for_each(begin(_vecValues), end(_vecValues), [&](std::vector<double> &v) {
std::vector<double> vcr;
_vecChangeRates.push_back(vcr);
double prevValue = v[0];
std::for_each(begin(v), end(v), [&](double &value) {
double changeRate = (value - prevValue) / prevValue;
_vecChangeRates[_vecChangeRates.size() - 1].push_back(changeRate);
prevValue = value;
});
});
}
12/06/12: Other people's work always seems much more interesting
... or, the grass is always greener on the other side, I suppose.
One of my habits is to read about cool projects people do with open-source hardware systems like the Raspberri Pi and Arduino, as well as look through interesting GitHub projects. I use a private GitHub repository for work (which I think is a great way to collaborate with remote developers), so it's always tempting to look around to see what other people are building.
It's all very cool, interesting stuff, but it always makes me feel a bit jealous. Reading about all the feats of engineering required to create a miniture MAME cabinet using a Raspberri Pi, for example, makes me want go out and attempt something similar.
What I just recently realized is that I do work on a lot of cool, hacker-eqsue stuff. Throughout my career as a programmer, I've run into lots of instances where I had to employ a novel solution to a tricky software or hardware problem, and I have a lot of stories to tell, but the problem is that all of my work is "closed-source", which is to say that I can't necessarily blog about my work because the code and technologies that I work on are trade secret.
As much as I would love to talk about the infrared gun tracking system used for the newer Big Buck Hunter games, for example, I'm not able to. Even though I don't work there anymore, I'm sure they wouldn't want me to spill the beans about how that particular piece of technology works. Not that I would want to do any bean spilling, anyways.
Much like the phenomenon of survivorship bias, there is a sort of "open-source" bias when it comes to the kinds of projects that get blogged about. Open-source projects that are predicated upon a certain level of collaboration are always going to get written about and discussed online, while there is next to nothing (which is appropriate) about what I assume to be the vast majority of projects occurring within private organizations.
Knowing this, it does take a bit of effort for me to realize that the systems that I
work on everyday are just as interesting and cool as what I read online. Just because
nobody has blogged about it, doesn't mean that it's not totally awesome.
- About -
My name is Manny Najera, and I'm a software engineer living and working in the Chicago area. Working in a variety of languages (most commonly C/C++/Java), I do a lot of work with embedded systems, low-level hardware interfaces and sensor networks.
I can be reached at: